myBlog
Be Different
Use of Structure Theorem, Array, and Modularization
Author: jonathanw9 Mar
In the previous article, we have discussed a little bit of Structure Theorem and array. Also the difference between procedural programming and object-oriented programming. In procedural programming, we divide general problem into more specific problems. In this article, Structure Theorem and array will be explained thoroughly, also introduction to modularization is given in this article.
STRUCTURE THEOREM
Structure Theorem is composed of sequential, selection, and repetition. Sequential means the program execution starts from top to bottom of the program. Selection is a representation of comparing two variables and take certain action(s). Repetition is repeating the same instruction(s) until certain condition is met. Below is the explanation and examples of selection and repetition.
- Selection
In pseudocode, there are two types of selection keywords. The first is IF…THEN…ELSE…ENDIF keywords to make simple selection. To have multiple selection options, rather than using nested ifs, we could use CASEOF…ENDCASE. In C, simple selection can be done using keywords if() and else(). Multiple selection options can also be done using keywords switch() and case.
- Repetition
In pseudocode, repetition has three categories, the first is leading, which in pseudocode is represented using keywords DOWHILE…ENDDO. This category examines the condition first, then if the condition is true, the following statements will be done. The second is trailing, which in pseudocode is represented using keywords REPEAT…UNTIL. Contrary to the first category, this category examines the condition at the tail of the repetition pseudocode. The last one is counted, which is represented using keyword DO…ENDDO. This category counts how many repetition has been done, and it stops after the repetition has been done for certain number/time.
ARRAY
Array, as explained in the previous article, is a data structure that consists data item of similar data type. In writing pseudocode, array can be written as array_name(array_size). In array, we can assign, process, search for, and display its values. These are the operations that can be done to an array.
In array, we know the term paired array. Paired array is not a two-dimensional array, but it is an array with equal size and each of its element corresponds to the element in the same index of another array. Both values are somehow bonded, but separate.
To search an array, two methods can be done: linear search and binary search. To do linear search, the elements in the array need not be sorted since linear search traverse each data exactly once. On the other hand, binary search needs to sort since binary search does comparison between the data searched and the middle data. Say we sort the array ascending, if the data searched is smaller than the middle data, the left side of the middle data will be used to search the data again; and vice versa.
MODULARIZATION
Modularization is needed to solve problem specifically, since it is the result of problem division. In pseudocode, the name of the module becomes the beginning of the pseudocode, ended with keyword END. The use of modularization is beneficial, because:
- it eases understanding,
- it is reusable,
- eliminates redundancy,
- and has good efficiency of maintenance.
To represent modularization and its structure, we can use hierarchy/structure chart. For example:
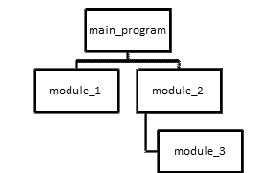
To do modularization, we can do the following steps:
- define the problem (input, process, output),
- group activities into modules,
- create the hierarchy chart,
- create the pseudocode for the mainline of the program,
- develop pseudocode for the modules,
- do desk checking.
Sometimes, we need to pass parameter in developing modular programming. To do so, we can use the following syntax:
module_name(param_1, param_2)
However, if we use the above syntax for passing parameter in pseudocode, we cannot apply the same syntax to write array declaration.
To conclude, the structure theorem is very useful in both designing pseudocode and writing program. Also, the use of array and modularization in developing pseudocode is essential. Therefore, proper practice of developing pseudocode is needed in order to master programming design methods.
Program Design: Introduction
Author: jonathanw25 Feb
Most of the time, when faced with a problem, programmers would quickly code to handle the problem. Rather than finishing the program quickly, most of these programmers are very likely to spend hours of creating the program, since they lack directions on what to do next. This topic examines the precise and efficient way of developing program, including writing good pseudocode and algorithm, so that programmers could work efficiently and produce the correct result and an error-free program.
PSEUDOCODE
A pseudocode is a way of interpreting or representing algorithm. Pseudocode consists of keywords (usually written in capital) and variables. The keywords are usually control statements, for instance, DOWHILE…ENDDO, IF…ELSE…ENDIF, and many more. Pseudocode could have modules or functions, also indentation. Usually, pseudocode is written using simple English, but it is fine if one is comfortable of using another language. What matters is that a pseudocode must be easy to be read and understood.
When we create a pseudocode, variables cannot be written as how keywords are written because differentiating keyword and variables will be difficult. Also, variables should not have meaningless name; its name should represent what the variables are for.
Pseudocode has three main characteristic, the first is general – meaning everyone who read it could understand what does the pseudocode do-, universal – meaning it is not bound to any programming language-, and consistency – for example, if the writer of a pseudocode uses keyword PRINT to print the output, he/she cannot use keyword WRITE to achieve the same goal as keyword PRINT does in the same pseudocode.
ALGORITHM
An algorithm is the steps to be taken or the logical flow of problem solving. As stated above, an algorithm can be represented using pseudocode, and to broaden reader’s knowledge, a flow chart could also be used to represent algorithm. A more explanation on flow chart will be provided in the upcoming article.
An algorithm must be precise – meaning an algorithm cannot be ambiguous-, produce correct output, and eventually end – the algorithm is not looping forever. In writing algorithm, indentation is needed to increase readability.
PROGRAM DEVELOPMENT FUNDAMENTALS
A program exists since there is a problem that needs to be handled. The main purpose of a program is to ease the user to handle a problem and produce the correct output as how the user wants it. So, the first step to develop a program is to identify the problem. Here, identifying the problem means finding out what are the inputs needed, processes to do, and the expected outputs. After the problem is identified, the possible problem’s solution(s) should be outlined. Simply do brainstorming of the possible solution(s), and shall there be many, choose one that is best suited to handle the problem. Next, the outline should be developed into an algorithm, and this algorithm must be tested for correctness. To check the algorithm, we can use a desk check table which will be elaborated in the upcoming article. Now, programmers can code the algorithm using the best suited programming language to solve the problem. It is also essential to check the code by running it, to see syntax or logical error. Last but not least, the program must be documented to ease other programmers who might take part in working with the program.
In developing a program, there are three most common methods:
- Procedure-driven – this method focuses on the processes needed. Procedure-driven method is not the same as procedural programming or top-down design. This method is usually used by programmers.
- Event-driven – this method focuses on the events caused by the user; mouse click, and many more. This method is usually used by system analyst.
- Data-driven – this method focuses on the data relation. This method is usually used by database administrator.
Aside from the methods above, the study of computer science also know the concepts of procedural and object-oriented programming. Procedural programming is a top-down development design, meaning the solution is divided gradually into more detail steps until all the detailed steps have been completed. This concept also includes modular design that allows a group of tasks be formed to perform the same function. On the other hand, object-oriented programming focuses on the objects and the behavior of the objects, so the process is not the main focus, but the objects used to solve the problem.
In computer science, it is also important to know the differences between variable, constant, and literal. Variable is a memory cell assigned to a specific value. The value of a variable can be changed during the program execution. On the other hand, a constant is a data that has a name and unchanging value during the execution. In C programming language, simply declare const. Literal is a constant as well, but literals have unique value and its name. For instance, the value of 3.14 is known as PHI (π), and PHI’s value is known as 3.14. There are no other values that can be assigned to literal PHI as its value is ‘bound’ to 3.14.
THE STRUCTURE THEOREM
The structure theorem is composed of the following:
- Sequence – means the execution of a code is straightforward; from top to below/down.
- Selection – actions can be done if the required condition is either true or false. In pseudocode, keywords that can be used are IF, IF…THEN…ELSE, and ENDIF.
- Repetition – actions can be done repeatedly while a condition is not met yet. In pseudocode, keywords that can be used are DOWHILE, REPEAT…UNTIL, DO, and ENDDO.
To conclude, an algorithm is the steps or actions to be taken to solve a problem, and a way to interpret it is to use pseudocode. It is important that writing conventions be used in writing algorithm and pseudocode. To efficiently produce good program, programmers should not directly code, but knowing the needs of the program and writing its algorithm should be the first thing done. Concepts and methods of designing program are very important, and rudimentary knowledge of variable, constant, and literal is essential. Lastly, the structure theorem is fundamental as it is used to design program.
Data Structure: Introduction
Author: jonathanw22 Feb
Data structure is simply a group of data elements put together under one name. The main goal of using data structure is to have good organization of data. Data structure has many applications in the real world, also many ways to implement it. It is imperative to understand that the following article will be based on C language. To begin this topic, we will go through array and pointer, followed by a brief description about data structure, and last, implementation examples of data structure, including linked list, stack, queue, and binary tree.
Before we study deeper, it is important to understand the following terms:
- Traversal means accessing each data elements exactly once to be processed.
- Searching is used to find a location of data elements that satisfy the given constraint(s). The data searched may or may not exist on the structure.
- Inserting means adding new data to the structure.
- Deleting means removing a data from the structure.
- Sorting is done to arrange data elements in order, either ascending or descending.
- Merging is combining two or more sorted data items to form a new single list of sorted data elements.
ARRAY
An array is a collection of similar data type, stored in consecutive memory location. The location of the array is referenced by an index (usually starting from 0). To declare an array, we must set the data type, then the array’s name, and the memory allocated or the size for that array. For example:
int num[10] (ex. 1)
The example above (ex. 1) will allocate 10 memory location for array num that can only contain integer data type, declared int above. The first element will be written as num[0] and the last element is called num[9]. Any attempt to enter more than 10 integers to the array num will result in buffer overflow.
![]()
Fig. 1 – Representation of array num[10]
So, we can conclude that to declare an array, the following syntax must be typed correctly:
data_type array_name[array_size]; <def. 1>
If more than one dimension array is needed, simply add [array_size] after the previous array size (data_type array_name[array_size1][array_size2];).
POINTER
A pointer is a variable of a data type that contains another variable’s location with the same data type the pointer has. Pointer points to an address of another variable to provide indirect access. The operators used are & and *. The & symbol is a symbol of address, and to access the value stored in the address, we use * symbol. The following is the syntax of pointer declaration:
data_type *pointer_name; <def. 2>
And to make the pointer points to another variable’s value, we can type the following:
pointer_name = &target_variable; <def.3>
The &target_variable is the address of variable target_variable, and by declaring <def. 2> and <def. 3>, we have a pointer pointer_name that points to the value of variable target_variable. This is called indirect access. And to be noted, a pointer can point to another pointer, typed **pointer_name;.
Good understanding of pointer is essential to ease the study of data structure. Therefore, if the reader has any difficulty to understand pointer, I recommend to search and study about pointer more.
DATA STRUCTURE
As stated before, a data structure is a group of data elements put together under one name. Data structure is grouped into two type, primitive and non-primitive. Primitive data structure are data types which are provided by the programming language, for instance, integer, character, float, and many more. On the other hand, non-primitive data structure is created using primitive data structures. The examples of non-primitive data structure are linked list, stack, trees, and graphs. If the elements in the data structure is stored sequentially, it is called linear structures; otherwise, it is called non-linear structures.
A data structure has three characteristics. The first is correctness, where the codes are successfully executed and execute well. The second characteristic is time complexity. In programming, programmers are required to create a program that can run with the smallest amount of time. The last characteristic is space complexity. Free memories are finite, therefore it is essential for programmers to be able to code a program that uses spaces/memories as small as possible. However, it is not easy to develop good program. Also, in using data structure, three main problem could be faced: data searching, the processor’s speed, and multiple requests. Thus, lots of practice and study is required to master data structure.
Since the concepts of data structure has been elaborated above, it is inappropriate if the basic concepts of data structure implementations are not explained. The following are the examples of data structure implementations with their brief description:
- Array
An array is a data structure since it is a collection of data elements, contained under one name. Array’s elements are stored in consecutive memory locations, and arrays are generally used to store large amount of similar data type. However, arrays can only store similar data type and are made of fixed size. Also, it can be problematic to do insertion and deletion of data because of shifting of elements from their positions.
- Linked list
A linked list is a very flexible and dynamic data structure since insertion and deletion can be done at any point. The memory used in linked list are not consecutive. A linked list can be either a single, double, circular, or multiple linked list. Each data element in linked list has a pointer that points to another element. The last element of a linked list could point back to the first element, or point to nowhere (point to NULL value).
Although insertion and deletion can be done easily, one may be confused with how linked list works at first. But as time flows, it will become easier.
![]()
Fig. 2 – Representation of linked list
- Stack
Technically, a stack uses principle known as LIFO or FILO (Last In First Out or First In Last Out). To understand this concept better, imagine a pile of disks. The last disk inserted to the pile will always be the first to be taken. The same principle applies to the stack concept.
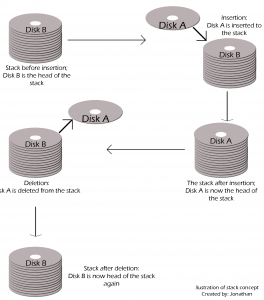
Fig. 3 – Illustration of stack (pile of disks)
- Queue
Slightly different than stack, a queue is a data type that has the following principle: insertion of new data element will become the tail/rear or the last element of the data structure, and the deletion from the queue must begin from the head/front or the first data element in the structure. This principle is known as FIFO (First In First Out).

Fig. 4 – Illustration of queue
(source: http://key-to-programming.blogspot.co.id/2015/02/queue-data-structure-queue-ds-queue.html)
- Binary Tree
A binary tree has elements (called nodes) that consist of one right pointer, one left pointer, and its data element. The left pointer points to another element that has smaller value than the data element, whereas the right pointer points to another element that has bigger value than the data element. A binary tree is usually used to do sorting, searching, creating artificial intelligence, and many more. Traversal of data can be done fast since each node has a maximum of two ‘children’ (left and right pointers).
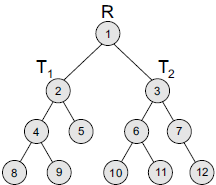
Fig. 5 – Representation of binary tree
To conclude, data structure is quite a topic to be mastered, but with proper training and understanding of the basic concepts used such as pointer, it will be easy to apply the implementations of data structure, such as array, linked list, stack, queue, and binary tree.
Source:
Reema Thareja,. 2014. Data structures using C. OXFORD. New Delhi. ISBN:978-0-19-809930-7 Chapter 1, 2, 3.
http://key-to-programming.blogspot.co.id/2015/02/queue-data-structure-queue-ds-queue.html
HTTP 2016
Author: jonathanw18 Sep

Halo semuanya! Baru-baru ini, lebih tepatnya tanggal 10 September 2016 kemarin, gua ikut acara Temu Keakraban Mahasiswa Baru Teknik Informatika Universitas Bina Nusantara yang lebih dikenal dengan nama HTTP 2016 (HIMTI Togetherness and Top Perfomance). Acara yang dilaksanakan oleh HIMTI (Himpunan Mahasiswa Teknik Informatika) tiap tahun sejak 2001 ini mengusung tema Passion, Innovation and Togetherness yang dilaksanakan di gedung BPPT II di Thamrin. Penasaran? Yuk simak artikel berikut ini!
Saat teman-teman satu jurusan gua sudah daftar ikut HTTP 2016 6 Agustus yang lalu, gua malah belum daftar. Pertimbangannya gua ada soal biaya (Rp. 150.000,00! X_X), lokasi gedungnya yang cukup jauh, dan terutama waktu yang gua takutin bakal tabrakan sama jadwal kuliah. Tapi, bujukan manis teman-teman gua berhasil meyakinkan gua untuk ikut HTTP 2016 dan akhirnya gua daftar lewat situs HTTP.
Gua pikir daftarnya ribet dan lama, tapi ternyata pendaftarannya sangat mudah, cepat, dan jelas. Dan ternyata, abis gua perhatiin lagi, Rp. 150.000,00 itu gak kemahalan, karena transportasi ke lokasi acara sudah dijamin, dapat kaos, souvenir dan banyak lagi.
Singkatnya, tibalah tanggal 10 September. Gua berangkat dari Kampus Alam Sutera jam 6 pagi, dan ternyata jam 7 pagi sudah sampai di lokasi, padahal acara baru akan dimulai jam 9 pagi XD.
Alhasil kami menunggu di dalam gedung sambil disuguhkan film “Zootopia”. Lagi asyik-asyiknya, mendadak filmnya dimatiin!!!
Ternyata udah jam 9 pagi, para peserta sudah datang dan acara pun dimulai. Acara dibuka dengan penampilan grup band Peanut Butter, yang sebenernya bagus sih, tapi kaya kurang persiapan gitu pas tampil; entah grogi atau memang kurang persiapan. Kemudian kami semua mendengarkan sambutan dari Ketua HTTP 2016, pengurus HIMTI, dan juga dari Bapak Andreas Chang beserta Dean of School of Computer Science (SoCS) dan perkenalan seluruh tim SoCS. Inti dari sambutan-sambutan ini sebenarnya bagus sih, ada tentang motivasi menjalani kuliah, cara sukses dalam hidup, dan banyak lagi, tapi waktu yang terlalu lama membuat banyak peserta malas bahkan ngantuk dengerin semua sambutan-sambutan.

Suasana saat acara
Setelah itu, beberapa peserta diajak bermain game lanjut kata. Jadi peserta pertama diberikan kata pertama, lalu peserta selanjutnya mengulang kata tersebut dan menambahkan kata dari dirinya sendiri, dan seterusnya. Ada satu peserta yang kata-katanya jones (jomblo ngenes) banget!
Lalu kami menyantap makan siang yang disediakan Kafe Ngemil. Nasi, ayam goreng, orek tempe, dan taoge yang setengah matang pun gua makan. Laper kan, jadi apapun enak :p.
Dan rupanya, ada stand-stand/booth-booth dari berbagai produk makanan dan minuman di lantai 4 gedung BPPT II. Ya gua samperin satu persatu, mungkin ada makanan atau minuman gratis dibagiin :D.
Setelah break makan siang selesai, kami mendengarkan talkshow dari 3 mahasiswa Binus yang berkarya, yaitu Christian Tanujaya dan Reynald dengan karya robot yang mampu berdongeng dan berinteraksi dengan penggunanya. Juga ada Natanael Febrianto yang menemukan aplikasi untuk mendeteksi kepribadian seseorang melalui tweet-nya di Twitter. Mereka sharing tentang gimana mereka masuk IT, ada yang kepaksa ada yang memang mau, terus juga gimana mereka buat karya mereka dan tips-tips buat kita-kita maba (mahasiswa baru). Keren!
Kemudian ada penampilan drama atau visualisasi HTTP 2016. Banyak adegan yang konyol dan lucu, tapi durasi yang kelamaan dan alur cerita yang terlalu diulur bikin visualisasi sedikit membosankan.

Visualisasi
Setelah visualisasi, kami menyaksikan performance dari Vibing High yang sangat menghibur. Suaranya enak, musiknya mantap, juga pembawaan lagu-lagu yang pol abis kaya Uptown Funk, dan banyak lagi deh!
Acara pun ditutup dengan pelantikan kami, maba SoCS, secara simbolis (memakai almamater) dan ‘dugem’ bareng DJ. Gila rame dan berisik banget wkwk!
Acara baru benar-benar selesai pukul 6 malam dan untungnya, pukul 7 malam gua sudah tiba lagi di Alam Sutera jadi bisa beristirahat di rumah.
Secara keseluruhan, HTTP 2016 sebenernya menghibur dan berguna, tapi ada beberapa kekurangan dalam pelaksanaannya yang gua yakin bisa diperbaiki dan bakal bikin HTTP 2017 lebih baik lagi. Salut panitia HTTP 2016! Great job!
Sekian dulu ya dari gua. Sorry yaa semua kalo gua ada salah tulis nama atau kalian kurang suka sama postingan gua yang ini. Tunggu posting saya yang berikutnya ya! Terima kasih sudah membaca!